本文记录学习的 Linux 命令
dd
快速生成文件
1 | // 生成 10M 的test文件 |
上述命令是实际写入硬盘,文件产生速度取决于硬盘读写速度,如果想要产生超大文件,速度很慢。
在某种场景下,我们只想让文件系统认为存在一个超大文件在此,但是并不实际写入硬盘。则可以使用 seek
1 | // count=0 表示读写 0 次,指定生成文件的大小为 0M |


1 | // count=50 表示读写 50 次,指定生成文件的大小为 50M |


此时创建的文件在文件系统中的显示大小为 1000MB,但是并不实际占用 block,因此创建速度与内存速度相当
du (disk use):默认显示的是真正的磁盘占用
1 | // 随机生成1百万个1K的文件 |
分割文件,合并文件
分割操作:
1 | // 一个块为128K,跳过前18块 |
合并操作:
1 | // 1.txt 和 2.txt 合成 3.txt |
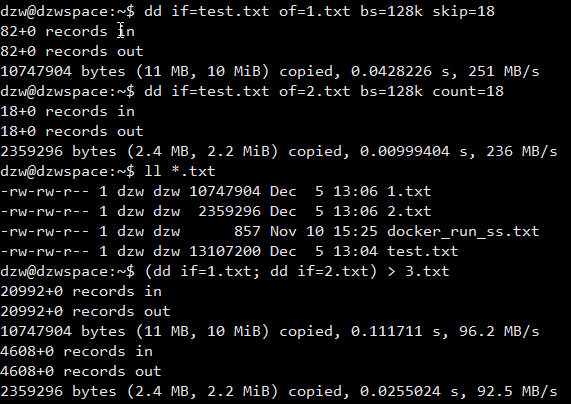
合并后的 3.txt 文件和 test.txt 文件的 md5 一致
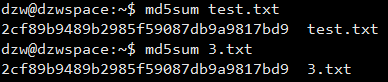
conv
将 testfile_1 文件中的所有英文字母转换为大写,然后转成为 testfile_2 文件
1 | $ cat testfile_1 |
管道查看器 pv
$ sudo apt-get install pv
$ dd if=/dev/zero | pv | dd of=test
if (input file) 代表输入文件/目录,如果不指定 if,默认就会从 stdin 中读取输入
of (output file) 代表输出文件/目录,如果不指定 of,默认就会将 stdout 作为默认输出
bs 代表每次读入的 block 大小
count 代表读取的 block 个数
bs*count = 文件大小
/dev/zero 是Linux提供的一个特殊的字符设备,它的特点是可以永远读该文件,每次读取的结果都是二进制0
seek 跳过输出文件中指定大小的部分,并不实际写入
skip 跳过输入文件开头指定大小再开始复制
if=文件名:输入文件名,默认为标准输入。即指定源文件。
of=文件名:输出文件名,默认为标准输出。即指定目的文件。
ibs=bytes:一次读入bytes个字节,即指定一个块大小为bytes个字节。
obs=bytes:一次输出bytes个字节,即指定一个块大小为bytes个字节。
bs=bytes:同时设置读入/输出的块大小为bytes个字节。
cbs=bytes:一次转换bytes个字节,即指定转换缓冲区大小。
skip=blocks:从输入文件开头跳过blocks个块后再开始复制。
seek=blocks:从输出文件开头跳过blocks个块后再开始复制。
count=blocks:仅拷贝blocks个块,块大小等于ibs指定的字节数。
conv=<关键字>,关键字可以有以下11种:
conversion:用指定的参数转换文件。
ascii:转换ebcdic为ascii
ebcdic:转换ascii为ebcdic
ibm:转换ascii为alternate ebcdic
block:把每一行转换为长度为cbs,不足部分用空格填充
unblock:使每一行的长度都为cbs,不足部分用空格填充
lcase:把大写字符转换为小写字符
ucase:把小写字符转换为大写字符
swab:交换输入的每对字节
noerror:出错时不停止
notrunc:不截短输出文件
sync:将每个输入块填充到ibs个字节,不足部分用空(NUL)字符补齐。
block 块大小可以使用的计量单位:
字节 (1B) c
字节 (2B) w
块 (512B) b
千字节 (1024B) k
兆字节 (1024KB) M
吉字节 (1024MB) G
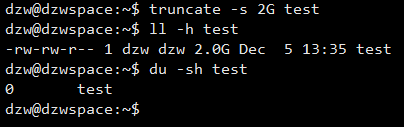
truncate
将文件缩减或扩展至指定大小。
选项 -s,即 size(大小)
- 指定文件不存在则创建。
- 指定文件超出指定大小则超出的数据将丢失。
- 指定文件小于指定大小则用0 补足。
注意点:
这种文件被称为“空洞文件”,文件的部分内容并没有实际存在于硬盘上
du (disk use):默认显示的是真正的磁盘占用
1 | // 创建 2G 的 test 文件 |

fallocate
tc
模拟网络异常场景(丢包/延迟等)
模拟延迟传输
1 | // 该命令将 eth0 网卡的传输设置为延迟 100 毫秒发送 |
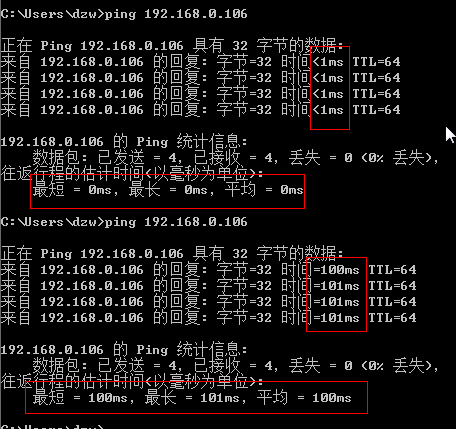
1 | // 带有波动性的延迟值 |
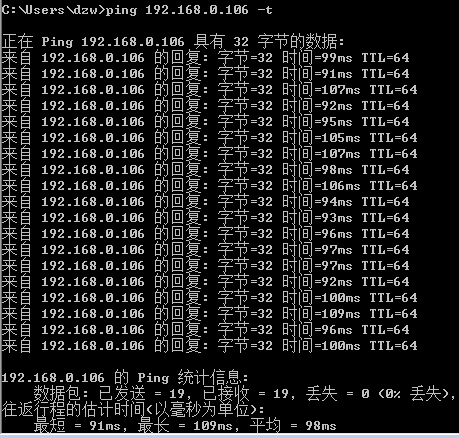
1 | // 该命令将 eth0 网卡的传输设置为 100ms ,同时,大约有 30% 的包会延迟 ± 10ms 发送 |
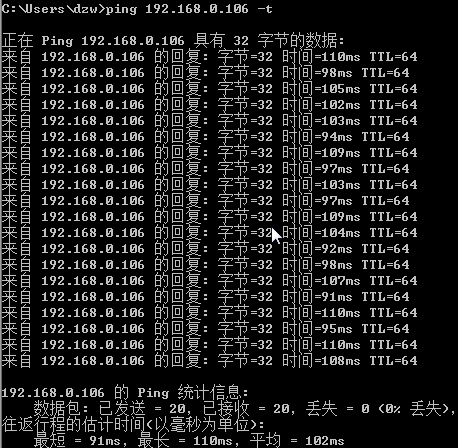
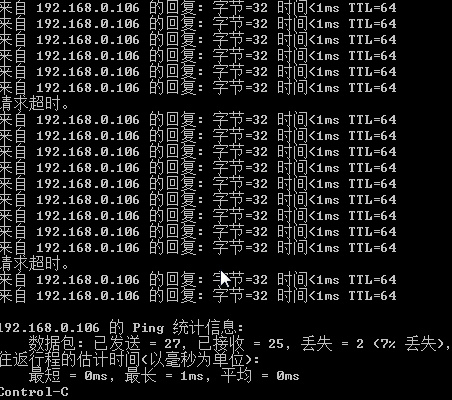
模拟网络丢包
1 | // 该命令将 eth0 网卡的传输设置为随机丢掉 10% 的数据包 |
1 | // 该命令将 eth0 网卡的传输设置为随机丢掉 10% 的数据包,成功率为 30% |
// 查看网卡上面的相关配置
1 | $ sudo tc qdisc ls dev eth0 |

// 删除网卡上面的相关配置
1 | // 该命令将 删除 eth0 网卡的相关传输配置 |
模拟包重复
1 | // 该命令将 eth0 网卡的传输设置为随机产生 1% 的重复数据包 |
模拟数据包损坏
1 | // 该命令将 eth0 网卡的传输设置为随机产生 0.2% 的损坏的数据包(内核版本需在 2.6.16 以上) |
模拟数据包乱序
1 | // 该命令将 eth0 网卡的传输设置为:有 25% 的数据包(50%相关)会被立即发送,其他的延迟10 秒 |